Abstract
This paper investigates whether increasing domain specific training on mathematical reasoning data reliably improves small language models (SMLs), and where the approach breaks down. We fine tune three small base or instruct models, Gemma3-270M, SmolLM-135M, and SmolLM2-360M-Instruct, using parameter efficient fine tuning (PEFT) methods (LoRA and QLoRA) on GSM8K. Early experiments exhibit severe degradation such as loss of coherent language, repetitive outputs, and unstable generation, indicating catastrophic forgetting and format or hyperparameter mismatch. A later experiment using an instruction tuned backbone (SmolLM2-360M-Instruct) shows measurable improvement, achieving 10% accuracy on GSM8K and 2% on MATH-500 under a small sample evaluation. Our findings suggest that for SMLs, training stability and alignment between model pretraining format and target dataset often matter more than simply adding more domain data.
1. Introduction
Small language models (SMLs) promise low cost deployment and faster iteration cycles, making them attractive for specialized assistants such as domain math tutors. However, SMLs have limited capacity and are more sensitive to fine tuning instability than larger models, especially when trained on narrow distributions such as mathematical word problems.
This work asks a practical question: how far can we push domain fine tuning on SMLs to make them smarter in a specific domain, and what are the failure modes when it does not work? To answer this, we fine tune multiple SML backbones on GSM8K using PEFT approaches and evaluate on GSM8K and MATH-500.
2. Background
Fine tuning adapts a pretrained model to a target distribution. In SMLs, three recurring issues can dominate outcomes:
- Catastrophic forgetting, where adaptation overwrites general language capability, causing degraded fluency or incoherent outputs.
- Data format mismatch, where the target training examples do not match the model instruction format or expected special tokens, harming generation behavior.
- Overfitting and repetition, where the model memorizes patterns and loops, often exacerbated by small model capacity, long training, or decoding issues such as missing EOS handling.
PEFT methods such as LoRA and QLoRA reduce compute and memory requirements by updating low rank adapters rather than full model weights, but they do not automatically prevent instability.
3. Experimental Setup
3.1 Datasets
We used GSM8K as the primary fine tuning dataset for grade school math reasoning. We also evaluated generalization using:
- GSM8K (held out evaluation samples)
- MATH-500 (subset evaluation)
Evaluation used 50 randomly sampled examples per benchmark in our runs, which provides a quick signal but has high variance.
3.2 Models
We trained three versions of Matbot:
- Matbot-1:
Gemma3-270M - Matbot-1.3:
SmolLM-135M - Matbot-1.4:
SmolLM2-360M-Instruct
A key difference is that SmolLM2-360M-Instruct is instruction tuned, which typically improves robustness when training and inference are chat or instruction formatted.
3.3 Fine tuning methods
We tested PEFT approaches:
- LoRA (low rank adaptation)
- QLoRA (quantized LoRA)
Across experiments, fine tuning was performed on GSM8K with the intent to improve math reasoning. Hyperparameters such as learning rate, rank r, batch size, training steps or epochs, and prompt templates should be reported in the final version. Missing details limit strict reproducibility.
3.4 Evaluation protocol
We measured accuracy as exact match correctness on final answers, as commonly done for GSM8K style evaluation. For MATH-500, we report the percentage of correct answers on the sampled subset.
4. Results
4.1 Observed behaviors by model
Matbot-1 (Gemma3-270M) degraded sharply after fine tuning. The model struggled to maintain basic coherent language and appeared to forget how to speak. This failure occurred with both LoRA and QLoRA.
Matbot-1.3 (SmolLM-135M) preserved basic fluency but produced garbage text and showed infinite repetitions. The behavior resembles overfitting or decoding instability, where the model collapses into loops rather than completing structured reasoning.
Matbot-1.4 (SmolLM2-360M-Instruct) showed clear progress. It remained coherent and achieved non trivial benchmark performance on both in domain (GSM8K) and harder out of domain (MATH) evaluation.
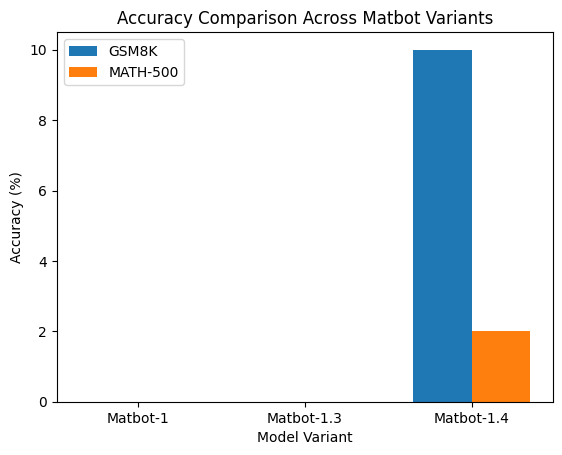
4.2 Quantitative results
| Model | Backbone | Tuning | GSM8K accuracy (50 samples) | MATH-500 accuracy (50 samples) | Primary failure mode |
|---|---|---|---|---|---|
| Matbot-1 | Gemma3-270M | LoRA / QLoRA | Not reliable (fluency collapse) | Not reliable | Catastrophic forgetting / instability |
| Matbot-1.3 | SmolLM-135M | LoRA / QLoRA | Not reliable (degenerate outputs) | Not reliable | Repetition / overfit like collapse |
| Matbot-1.4 | SmolLM2-360M-Instruct | LoRA (PEFT) | 10% | 2% | Limited capacity but stable |
5. Discussion
5.1 Why Matbot-1 likely collapsed
The forgot how to speak symptom strongly suggests catastrophic forgetting or training instability. In SMLs, this can happen when:
- Learning rate or adapter scale is too aggressive for the model size
- Too many steps on a narrow distribution bias the model away from general language
- Prompt formatting differs from what the base model expects (missing chat template, role tokens, separators, or EOS)
- Tokenization or template mismatch causes the model to learn odd continuations and degrade general decoding
The fact that both LoRA and QLoRA produced similar collapse implies the dominant issue was not quantization, but training setup and distribution shift.
5.2 Why Matbot-1.3 repeated garbage
Repetitive loops can appear when the model over specializes to frequent substrings, when EOS tokens are not learned or emitted, or when training data encourages long solution like continuations without clean termination patterns. With only 135M parameters, SmolLM may also lack the representational capacity to learn multi step reasoning from GSM8K without destabilizing its language modeling prior.
This failure mode is consistent with overfitting (too many epochs or too high effective update size), but it can also arise from inference time sampling (temperature, repetition penalty) or missing stop tokens. In practice, both training and decoding often contribute.
5.3 Why Matbot-1.4 improved
Matbot-1.4 benefited from three compounding advantages:
- Instruction tuned base:
SmolLM2-360M-Instructaligns better with prompt response training and produces more stable completions - More capacity:
360Mparameters provide more headroom for learning reasoning patterns than135M - Better compatibility with PEFT: LoRA works best when the backbone already has strong general instruction following behavior; adapters can then specialize without destroying fluency
The measured accuracy of 10% on GSM8K and 2% on MATH-500 remains low, but it is meaningful given the model size and the instability seen in earlier runs.
6. Limitations
This study used small sample evaluation (50 items per benchmark), which introduces high variance and makes small differences hard to interpret. Additionally, the experiments do not report critical hyperparameters (learning rate, LoRA rank, steps, batch size, context formatting), which prevents strict reproducibility and makes it harder to isolate which factor caused each failure mode.
Finally, since GSM8K is a narrow domain, improvements may reflect formatting alignment rather than general reasoning gains. Broader evaluations such as arithmetic, symbolic tasks, and out of distribution word problems would strengthen conclusions.
7. Conclusion and findings
This work demonstrates that for small language models under 400M parameters, more domain training does not reliably make the model smarter. Instead, it can degrade core language ability or cause degenerate generation. Across three Matbot variants, we observed two major breakdowns: catastrophic forgetting (loss of fluency) and repetition collapse (infinite loops), even when using PEFT (LoRA or QLoRA). The most consistent improvement came from switching to an instruction tuned backbone (SmolLM2-360M-Instruct), which produced stable outputs and achieved 10% accuracy on GSM8K and 2% on MATH-500 (each on 50 random samples). Overall, the results suggest that model choice and instruction format alignment are first order drivers of success in SML math fine tuning, while PEFT alone does not guarantee stability.